
The challenge of protecting sensitive data while using it to optimize efficiency and effectiveness has never been more challenging for businesses. Unsurprisingly, solving this challenge will only grow in importance and complexity as the cybersecurity threat and regulatory compliance landscapes continually shift. This post examines data anonymization vs data masking, two methods used to safeguard sensitive data but with different approaches and use cases.
We will highlight the main differences between each method, their benefits, common types and techniques, and real-world applications across industries. Additionally, this blog outlines best practices for implementing effective data anonymization and masking strategies, ensuring regulatory compliance, and reducing the risks of data breaches. Understanding these concepts is vital for organizations aiming to balance data privacy and utility.
What Is Data Anonymization?
Data anonymization is the process of protecting private or sensitive data by randomizing or encrypting any information that could link that data to specific individuals, business processes, or company secrets. The goal is to preserve data privacy while allowing the data to be used for analysis, research, or other necessary business purposes.
Common Data Anonymization Types and Techniques
Here are the common data anonymization types and techniques
Types:
- Pseudonymization: Pseudonyms replace identifiers that can be traced back to the original data.
- Masking/Obfuscation: Blurs or replaces sensitive data with fictitious but realistic values.
- Generalization: Replaces precise data with ranges or categories.
- Suppression: Removes or redacts sensitive data elements entirely.
- Synthetic data generation: Creates entirely new realistic data that mimics the original.
- Differential privacy: Adds controlled noise to obscure individual identities.
The choice of technique depends on the level of anonymization required, the type of data being anonymized, and the intended use case for the anonymized data.
Data Anonymization Benefits
Here are some key benefits of data anonymization:
Privacy protection: Anonymization safeguards sensitive personal information and prevents the misuse or unauthorized disclosure of data, helping organizations comply with data privacy regulations like GDPR and HIPAA.
Enables data sharing: By removing identifiers, freely sharing anonymized data, whether it be for research, analysis, or collaborative purposes, without compromising individual privacy, can be done safely.
Mitigates risk: Anonymizing data reduces the risk of data breaches which, in turn, reduces potential negative financial or regulatory compliance ramifications for organizations.
Fosters trust: Implementing robust anonymization practices demonstrates an organization’s commitment to data privacy and building trust with customers, partners, and stakeholders.
Enables monetization: Anonymized datasets can be monetized or leveraged for commercial purposes, such as developing new products or services, without exposing personal information.
Facilitates innovation: Anonymized data can drive innovation by enabling research, testing, and modeling across various domains, from healthcare to finance and beyond.
Legal compliance: Anonymization helps organizations meet data privacy and protection requirements set by various laws and regulations.
Ethical considerations: Anonymizing data aligns with ethical principles of respecting individual privacy and autonomy over personal information.
By balancing data utility with privacy protection, data anonymization provides a valuable tool for organizations to leverage data responsibly and ethically while mitigating risks and fostering trust.
Use Cases for Data Anonymization
Data anonymization has several common use cases and real-world examples across various industries and sectors:
Healthcare and Medical Research:
Anonymizing patient records and medical data for research purposes, clinical trials, or sharing with third-party collaborators while protecting patient privacy.
Example: Pharmaceutical companies anonymize patient data from clinical trials to analyze drug efficacy and side effects.
Financial Services and Banking:
Anonymizing customer financial data, transaction records, and account information for regulatory compliance, fraud detection, or internal analysis.
Example: Banks anonymize customer data to develop and test new financial products or services while maintaining confidentiality.
Marketing and Customer Analytics:
Anonymizing customer data, purchase histories, and online behavior for marketing campaigns, targeted advertising, or market research.
Example: E-commerce companies anonymize customer data to analyze shopping patterns and improve product recommendations.
Government and Public Sector:
Anonymizing citizen data, census information, or survey responses for statistical analysis, policy development, or sharing with research institutions.
Example: Government agencies anonymize census data to study demographic trends while protecting individual privacy.
Academic and Scientific Research:
Anonymizing data from studies, surveys, or experiments for publication, collaboration, or further analysis by the research community.
Example: Universities anonymize participant data from psychological studies to share findings while maintaining confidentiality.
Transportation and Logistics:
Anonymizing location data, travel patterns, and vehicle information for analysis, optimization, or sharing with third-party service providers.
Example: Ride-sharing companies anonymize rider data to improve route planning and service efficiency.
Social Media and Online Platforms:
Anonymizing user data, activities, and preferences for targeted advertising, algorithm training, or sharing with partners.
Example: Social media platforms anonymize user data to develop and test new features or personalization algorithms.
What Is Data Masking?
Also known as data obfuscation, data masking protects actual data by substituting it with fictitious yet structurally similar data. It minimizes the risk of sensitive data exposure, ensuring the data’s usefulness for software testing and training while keeping the actual information secure.
Common data masking types and techniques:
Static Data Masking:
- Substitution with fixed values: Replaces sensitive data with constant values like ‘XXX.’
- Shuffling/Substitution from lookup tables: Replaces real values with fictitious values from lookup tables.
- Character masking: Masks parts of data strings, such as showing only the last four digits.
- Encryption: Encodes data into ciphertext using encryption algorithms.
Dynamic Data Masking:
- Masking on the fly: Data is masked at runtime based on user roles/permissions.
- Partial masking: Only portions of sensitive data are masked.
Irreversible Masking:
- Hashing: Converts data into a fixed-length hash value using algorithms like SHA-256.
- Truncation: Removes parts of data, like showing only initial characters.
- Nulling/Deletion: Replaces sensitive data with null values or deletes it entirely.
Reversible Masking:
- Encryption: Encryption where original data can be retrieved with keys.
- Character shuffling: Rearranges characters in data like ‘ABC’ becomes ‘CBA’.
- Word/number substitution: Replaces words/numbers with other values.
Format Preserving:
- Deterministic encryption: The same input produces the same encrypted output.
- Format-preserving encryption (FPE): Encrypts while preserving data format like number lengths.
- Secure lookup tables: Replaces values using pre-built secure lookup tables.
The choice depends on factors like reversibility needs, data integrity, performance, and security and compliance requirements.
Data Masking Benefits
Data masking obfuscates or replaces sensitive data with fictional but realistic information, maintaining the structure of the original data. This technique protects sensitive data while preserving its usability for secure analysis, testing, and development by authorized personnel. It ensures compliance with data protection regulations by preventing the exposure of sensitive data in production application environments. Additionally, it mitigates the risk of data breaches, as the data, if accessed by someone without a need to know, does not reveal sensitive information.
Use Cases for Data Masking
Data masking is particularly useful in enterprise resource planning (ERP) applications and software testing and development environments, where using real data can pose privacy risks. Training environments also employ data masking to provide trainees with realistic data without exposing sensitive information. Additionally, it is used for data analysis and reporting where revealing real data could violate privacy laws or regulations.
Key Differences Between Data Anonymization and Data Masking
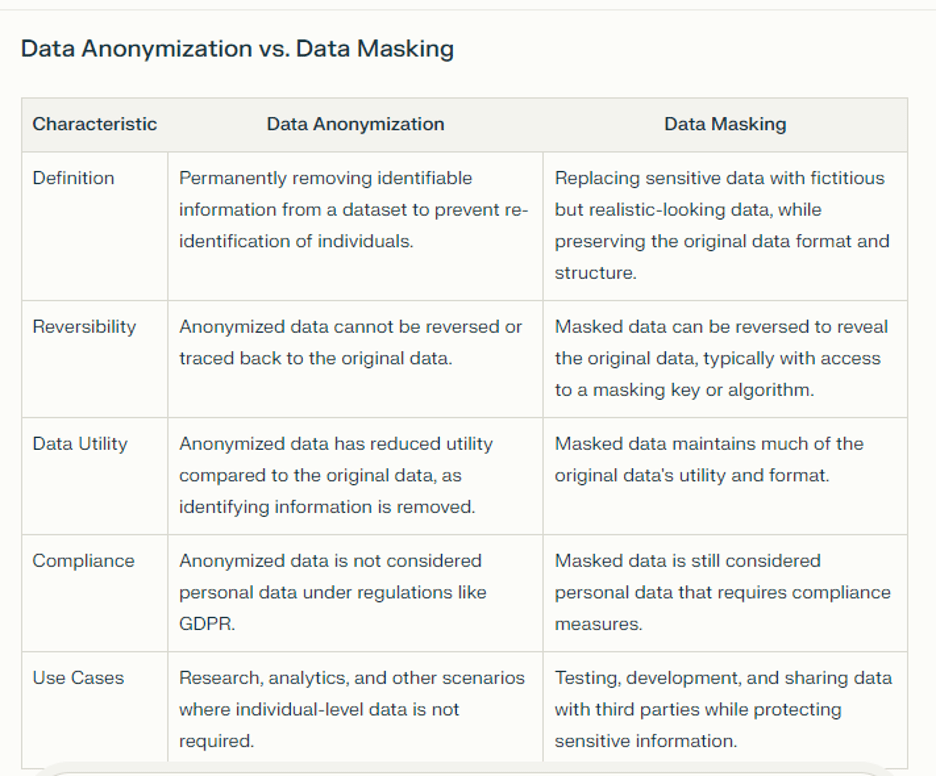
Data anonymization and data masking, two primary data security techniques, protect sensitive information in different ways. Understanding their key differences, such as security level, reversibility, use cases, and regulatory compliance, is essential.
Security Level
Data anonymization provides high-level security by irreversibly transforming data, making it unidentifiable, and eliminating any link to the data source. This approach nullifies data breach risks. In contrast, data masking conceals actual data without altering it. While this method enhances data security, its effectiveness depends on the robustness of the masking method. A weak masking method could leave the original data inferable or decipherable.
Reversibility
The reversibility of data anonymization and data masking differs significantly. Data anonymization is a one-way process—it’s irreversible. Once data undergoes anonymization, it can’t revert to its original state. Conversely, data masking is often reversible, depending on the specific technique. Methods like encryption or tokenization allow retrieval of the original data when needed, offering more flexibility in data usage.
Use Cases
Data anonymization and data masking serve different purposes due to their distinct characteristics. Data anonymization is ideal when the data source’s identity must be completely removed, such as in publicly shared data sets or research studies. However, data masking’s reversible nature makes it suitable for environments like business applications and software testing and training, where data must remain usable without exposing sensitive information.
Regulatory Compliance
Data anonymization and data masking both meet the data protection requirements of key regulations like the General Data Protection Regulation (GDPR), the Health Insurance Portability and Accountability Act (HIPAA), and the California Consumer Privacy Act (CCPA). Their compliance varies based on the specific regulation. For example, under GDPR, anonymized data is not considered personal data and is not subject to the regulation, whereas reversible masked data may still fall under GDPR’s scope.
Best Practices for Implementing Data Anonymization and Data Masking
A strategic approach is necessary when adopting data anonymization and data masking. Here are a few recommended practices:
Assess Data Sensitivity
Prior to applying any data protection technique, determine the sensitivity of your data. The level of protection needed varies and understanding this can guide your choice between data anonymization and data masking. Irreversible anonymization may be best for highly sensitive data, while data masking may suffice for less critical data or data that requires ongoing access and analysis.
Choose The Right Tools
Your choice of tools and technologies is crucial to effective data protection. Numerous solutions exist for both data anonymization and data masking. Your specific needs and data types should guide your selection. Choose tools that offer robust security features and integrate well with your existing IT environment.
Monitor and Update Regularly
Data security requires ongoing monitoring and updates. Regularly assess the effectiveness of your data protection measures and make necessary updates to ensure continued protection. Stay current with emerging threats and advancements in data security technologies.
Ensure Compliance and Documentation
Compliance with data protection regulations is mandatory. When implementing data anonymization or data masking, ensure you meet the requirements of relevant laws and regulations. Keep meticulous records of your data protection measures to demonstrate compliance during audits or inspections.
Dynamic Data Masking with Pathlock
The Dynamic Access Controls (DAC) product from Pathlock is built on an Attribute-Based Access Control (ABAC) security model. This enables a customizable and scalable, policy-based approach to data security, governance, and access control. Since the module’s dynamic data masking capabilities are governed by these easily configured ABAC policies, you can ensure that sensitive SAP data and transactions will be obfuscated without fail in scenarios where user access or actions indicate risk as defined in your organization’s custom policies.
The module’s centralized ABAC policy administration capabilities ensure that you can easily define and apply granular, dynamic access control policies without the need for redundant policy administration efforts on a per-role basis. With an intuitive user interface, customizing the out-of-the-box policies or creating your own is as easy as selecting filters to apply and requires no technical expertise for configuration.
Ultimately, the DAC module provides a least-privilege security approach that goes beyond traditional access controls, allowing organizations to ensure data security while still allowing employees to perform their necessary duties on a need-to-know basis.
Sign up for a demo today to see how Pathlock can protect your data while enabling your users to work in a secure and compliant access environment.

